

{kind=link}
El pionero del aprendizaje profundo Yann LeCun ha recibido muchos premios y elogios, pero quizá su máximo honor (aunque friki) sea que le dedicaran una cuenta paródica de Twitter, muy divertida y con muchos seguidores, que lleva el nombre de “Bored Yann LeCun” (Yann LeCun aburrido). La cuenta, que es anónima y se describe como “Reflexiones sobre el auge del aprendizaje profundo en el tiempo libre de Yann”, suele terminar sus ingeniosos tuits con el hashtag #FeelTheLearn (Siente lo aprendido).[1]
De hecho, las noticias sobre los últimos avances de la IA en los medios de comunicación “sienten lo aprendido” cuando celebran el poder del aprendizaje profundo, con énfasis en el “aprendizaje”. Nos dicen, por ejemplo, que “ahora podemos construir sistemas que aprenden a hacer tareas por sí solos”,[2] que “el aprendizaje profundo [permite] a los ordenadores enseñarse textualmente a sí mismos”[3] y que los sistemas de aprendizaje profundo aprenden “de manera similar al cerebro humano”.[4]
En este capítulo examinaré con más detalle cómo aprenden las máquinas –en particular las ConvNet [redes neuronales convolucionales o, para la mayoría de la gente del sector, ConvNet o CNN por sus siglas en inglés]– y en qué se diferencian sus procesos de aprendizaje de los de los humanos. Además, analizaré en qué afectan las diferencias entre el aprendizaje de las ConvNet y el de los humanos a la solidez y fiabilidad de lo aprendido.
Aprender por sí solas
El método de aprendizaje a partir de datos de las redes neuronales profundas ha demostrado tener más éxito, en general, que “la vieja estrategia de IA de toda la vida” en la que los programadores humanos elaboran unas reglas explícitas para obtener un comportamiento inteligente. Sin embargo, en contra de lo que se lee en algunos medios, el proceso de aprendizaje de las ConvNet se parece poco al de los humanos.
Como hemos visto, las mejores ConvNet aprenden mediante un procedimiento de aprendizaje supervisado: cambian gradualmente los pesos a medida que procesan los ejemplos del conjunto de datos de entrenamiento una y otra vez, a lo largo de muchas épocas (es decir, muchas repeticiones con los datos de entrenamiento), aprendiendo a clasificar cada entrada dentro de un conjunto fijo de posibles categorías de salida. Por el contrario, los niños, ya desde muy pequeños, aprenden un conjunto abierto de categorías y pueden reconocer casos de la mayoría de las categorías después de ver solo unos cuantos ejemplos. Además, los niños no aprenden de forma pasiva: hacen preguntas, piden información sobre las cosas que despiertan su curiosidad, deducen abstracciones y conexiones entre conceptos y, sobre todo, exploran el mundo.
No se puede decir que las ConvNet actuales aprenden “solas”. Como vimos en el capítulo anterior, para que una ConvNet aprenda a hacer una tarea es necesario un enorme esfuerzo humano que permita recopilar, organizar y etiquetar los datos, además de diseñar todos los aspectos de su arquitectura. Aunque las ConvNet utilizan la retropropagación para aprender sus “parámetros” (es decir, los pesos) a partir de los ejemplos de entrenamiento, el aprendizaje es posible gracias a una serie de “hiperparámetros”, un término genérico que abarca todos los aspectos de la red que el ser humano debe configurar solo para que el aprendizaje pueda comenzar. Entre esos hiperparámetros están el número de capas de la red, el tamaño de los “campos receptivos” de las unidades en cada capa, cuánto debe cambiar cada peso durante el aprendizaje (la llamada tasa de aprendizaje) y muchos otros detalles técnicos del proceso de entrenamiento. Esta parte de la configuración de una ConvNet se denomina ajuste de los hiperparámetros. Hay muchos valores que ajustar y complicadas decisiones de diseño que tomar, y esos ajustes y diseños tienen una relación compleja que influye en el comportamiento final de la red. Además, las decisiones sobre esos ajustes y diseños deben volver a tomarse ante cada tarea para la que es entrenada una red.
Ajustar los hiperparámetros puede parecer bastante rutinario, pero es absolutamente crucial hacerlo bien para el éxito de las ConvNet y otros sistemas de aprendizaje automático. Como el diseño de estas redes no está cerrado, en general no es posible establecer de forma automática todos los parámetros y diseños, ni siquiera con la búsqueda automatizada. Muchas veces hace falta una especie de conocimiento cabalístico que los estudiantes de aprendizaje automático adquieren tanto a través de su formación con expertos como de la experiencia adquirida con tanto esfuerzo. Como dice Eric Horvitz, director del laboratorio de investigación de Microsoft: “Ahora mismo, lo que estamos haciendo no es una ciencia, sino una especie de alquimia”.[5] Y estos “encantadores de redes” forman un club pequeño y selecto: según Demis Hassabis, cofundador de Google DeepMind, “sacar lo mejor de estos sistemas es casi un arte… No hay más que unos cientos de personas en el mundo capaces de hacerlo realmente bien”.[6]
En realidad, el número de expertos en aprendizaje profundo está aumentando a toda velocidad; muchas universidades ofrecen ya cursos sobre el tema, y hay cada vez más empresas con sus propios programas de formación en aprendizaje profundo para sus empleados. Pertenecer al club del aprendizaje profundo puede ser bastante lucrativo. En una conferencia a la que asistí hace poco, un directivo del grupo de productos de IA de Microsoft habló sobre la campaña de la empresa para contratar a jóvenes ingenieros especializados en aprendizaje profundo: “Si un chico sabe entrenar cinco capas de redes neuronales, puede pedir un salario de cinco cifras. Si sabe entrenar cincuenta capas, puede pedir un salario de siete cifras”.[7] Por suerte para ese chico al que le espera tanta riqueza, las redes todavía no pueden aprender por sí solas.
Macrodatos
No es ningún secreto que el aprendizaje profundo necesita grandes volúmenes de datos. Grandes quiere decir más de un millón de imágenes de entrenamiento etiquetadas en ImageNet. ¿De dónde proceden todos esos datos? La respuesta es, por supuesto, que de ti y probablemente de todos tus conocidos. Las aplicaciones modernas de visión por ordenador solo son posibles gracias a los miles de millones de imágenes que los usuarios de internet suben y (a veces) etiquetan con un texto que identifica lo que aparece. ¿Alguna vez han subido una foto de un amigo a Facebook y la han comentado? Facebook se lo agradece. Esa imagen y ese texto pueden haber servido para entrenar su sistema de reconocimiento facial. ¿Alguna vez han subido una imagen a Flickr? En ese caso, es posible que su imagen forme parte del conjunto de entrenamiento de ImageNet. ¿Alguna vez han identificado una imagen para demostrar en una web que no son un robot? Esa identificación quizá ha ayudado a Google a etiquetar una imagen para usarla en el entrenamiento de su sistema de búsqueda de imágenes.
Las grandes empresas tecnológicas ofrecen muchos servicios gratuitos en el ordenador y el teléfono móvil: búsqueda en internet, videollamadas, correo electrónico, redes sociales, asistentes personales automatizados…, una lista interminable. ¿Qué salen ganando? Quizá han oído decir que su verdadero producto son sus usuarios (como usted y como yo); los clientes son los anunciantes que captan nuestra atención y adquieren información sobre nosotros mientras utilizamos estos servicios “gratuitos”. Pero hay una segunda respuesta: cuando utilizamos los servicios de empresas tecnológicas como Google, Amazon y Facebook, estamos proporcionando directamente a esas empresas ejemplos –imágenes, vídeos, mensajes de texto o voz– que pueden aprovechar para entrenar mejor sus programas de IA. Y esos programas mejorados atraen a más usuarios (y, por tanto, recogen más datos), lo que hace que los anunciantes puedan dirigir sus anuncios de forma más eficaz. Además, los ejemplos de entrenamiento que les proporcionamos pueden servir para entrenar y ofrecer a otras empresas servicios “de oficina”, como la visión por ordenador y el procesamiento del lenguaje natural, a cambio de dinero.
Se ha escrito mucho sobre la ética de estas grandes empresas que utilizan los datos que creamos nosotros (por ejemplo, todas las imágenes, los vídeos y los textos que colgamos en Facebook) para entrenar programas y vender productos sin decírnoslo ni compensarnos. Es un debate importante, pero se sale del ámbito de este libro.[8] Lo que me interesa aquí es que la dependencia de extensas colecciones de datos de entrenamiento etiquetados es una diferencia más entre el aprendizaje profundo y el aprendizaje humano.
Con la proliferación de sistemas de aprendizaje profundo en aplicaciones del mundo cotidiano, las empresas necesitan nuevos conjuntos de datos etiquetados para entrenar redes neuronales profundas. Un ejemplo destacable son los vehículos autónomos. Estos coches necesitan una visión por ordenador avanzada para reconocer los carriles de la carretera, los semáforos, las señales de stop y otros elementos, así como para distinguir y seguir la pista de distintos tipos de posibles obstáculos: otros coches, peatones, ciclistas, animales, conos de tráfico, cubos de basura volcados, matojos rodadores y cualquier otra cosa con la que no conviene chocar. Los coches autónomos tienen que aprender a identificar esos objetos –con sol, lluvia, nieve o niebla, de día o de noche– y a determinar cuáles pueden moverse y cuáles no. El aprendizaje profundo facilita esa tarea, al menos en parte, pero, como en otros ámbitos, necesita una enorme cantidad de ejemplos de entrenamiento.
Las empresas de vehículos autónomos recogen esos ejemplos de entrenamiento en un sinnúmero de horas de vídeo grabadas por cámaras desde coches que circulan en medio del tráfico de calles y carreteras. Los coches pueden ser prototipos de conducción autónoma que las empresas están probando o, en el caso de Tesla, coches conducidos por clientes que, al comprar un vehículo, tienen que aceptar una política de intercambio de datos con la empresa.[9]
Los propietarios de Tesla no tienen obligación de etiquetar todos los objetos que aparecen en los vídeos grabados por sus coches. Pero alguien tiene que hacerlo. En 2017, el Financial Times informó de que “la mayoría de las empresas que desarrollan esta tecnología emplean a cientos e incluso miles de personas, muchas veces en centros deslocalizados en India o China, cuyo trabajo consiste en enseñar a los coches robot a reconocer peatones, ciclistas y otros obstáculos. Los empleados marcan o “etiquetan” manualmente miles de horas de vídeo, a menudo fotograma a fotograma”.[10] Han nacido nuevas empresas que proporcionan el servicio del etiquetado de datos; por ejemplo, Mighty AI ofrece “los datos etiquetados que necesitas para entrenar tus modelos de visión por ordenador” y promete “anotadores conocidos, verificados y de confianza, especializados en datos de conducción autónoma”.[11]
La cola larga
El método de aprendizaje supervisado, que utiliza grandes conjuntos de datos y ejércitos de anotadores humanos, funciona bien al menos para parte de las aptitudes visuales que necesitan los coches autónomos (muchas empresas están investigando también el uso de programas de conducción simulada, similares a los videojuegos, para reforzar el entrenamiento). Pero ¿qué sucede en otros aspectos de la vida? Prácticamente todos los que trabajan en el campo de la IA coinciden en que el aprendizaje supervisado no es un método viable para la IA de espectro general. Como ha advertido el prestigioso investigador sobre IA Andrew Ng: “La necesidad de tantos datos es una de las principales limitaciones actuales [del aprendizaje profundo]”.[12] Yoshua Bengio, otro destacado investigador de IA, está de acuerdo: “No es realista pensar que podemos etiquetar todo lo que hay en el mundo y explicar meticulosamente hasta el último detalle al ordenador”.[13]
El problema se ve agravado por la llamada cuestión de las colas largas: la gran variedad de posibles situaciones inesperadas con las que puede encontrarse un sistema de IA. La figura 1 ilustra este fenómeno mostrando la probabilidad de que se produzcan varias situaciones hipotéticas con las que puede encontrarse un coche autónomo, por ejemplo, circulando durante un día. Las situaciones muy corrientes, como toparse con un semáforo en rojo o una señal de stop, se clasifican como muy probables; las situaciones con una probabilidad media son, por ejemplo, cristales rotos y bolsas de plástico azotadas por el viento, que no se encuentran todos los días (dependiendo de por dónde circule el coche), pero no son infrecuentes. Menos probable es que el coche autónomo se encuentre con una carretera inundada o con los carriles tapados por la nieve, y todavía menos que se tope con un muñeco de nieve en medio de una autopista.
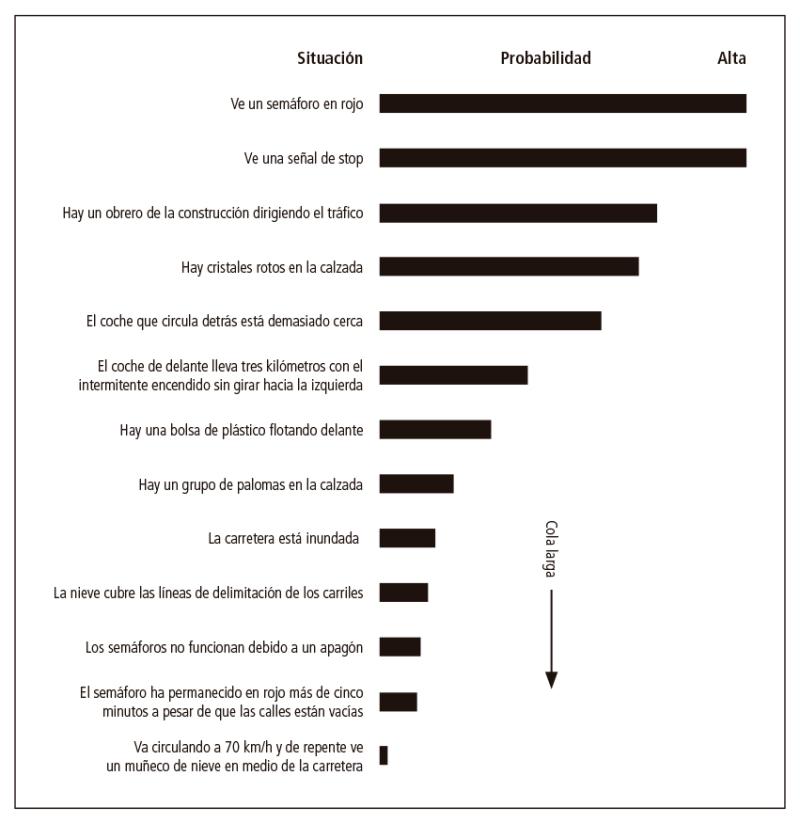
Se me han ocurrido estas situaciones y he calculado sus probabilidades; seguro que a cada persona se le ocurren muchas más. Probablemente, cada uno de estos coches es seguro: al fin y al cabo, en total, los coches autónomos experimentales han recorrido ya millones de kilómetros y han causado un número relativamente pequeño de accidentes (aunque algunos han sido mortales y han tenido gran repercusión). Ahora bien, cuando los coches autónomos se generalicen, aunque cada situación concreta improbable sea, por definición, muy improbable, hay tantas situaciones posibles en el mundo de la conducción y tantos coches que sí es probable que algún coche autónomo, en algún lugar y en algún momento, se encuentre con una de esas situaciones.
El término “cola larga2 procede de la estadística, en la que ciertas distribuciones de probabilidad tienen una forma similar a la de la figura 1: la larga lista de situaciones muy improbables (pero posibles) es la “cola” de la distribución. (Las situaciones que forman la cola se denominan a veces casos extremos).

La mayoría de los ámbitos reales en los que actúa la IA contienen este fenómeno de cola larga: los acontecimientos del mundo real suelen ser predecibles, pero queda una larga cola de sucesos inesperados y poco probables. Eso supone un problema si, para proporcionar a nuestro sistema de IA su conocimiento del mundo, nos fiamos únicamente del aprendizaje supervisado; las situaciones de la cola no aparecen suficientes veces en los datos de entrenamiento, si es que aparecen, por lo que hay más probabilidades de que el sistema cometa errores cuando se encuentre con esos casos inesperados.
Mostraré dos ejemplos reales. En marzo de 2016 se preveía una gran tormenta de nieve en el nordeste de Estados Unidos y en Twitter aparecieron informaciones de que el modo Autopilot de los vehículos Tesla, que permite una conducción autónoma limitada, confundía las líneas de los carriles y los montones de sal colocados en línea en la autopista en previsión de la tormenta (figura 2). En febrero de 2016, uno de los prototipos de coches autónomos de Google, que estaba girando a la derecha, tuvo que virar a la izquierda para evitar unos sacos de arena en el arcén derecho de una carretera de California y golpeó con la parte delantera izquierda un autobús público que circulaba por el carril izquierdo. Cada vehículo había contado con que el otro le cediera el paso (quizá el conductor del autobús pensaba que un conductor humano se sentiría intimidado por el autobús, mucho más grande).
Las empresas que desarrollan la tecnología de vehículos autónomos son muy conscientes del problema de la cola larga: sus equipos no paran de imaginar posibles situaciones de cola larga y crean sin cesar nuevos ejemplos de formación y estrategias codificadas especialmente para todas las situaciones poco probables que se les ocurren. Pero está claro que es imposible entrenar o codificar un sistema para todas las situaciones posibles.
Una solución que suele proponerse es que los sistemas de IA utilicen el aprendizaje supervisado con pequeñas cantidades de datos etiquetados y adquieran todo lo demás mediante aprendizaje no supervisado. “Aprendizaje no supervisado” engloba un vago conjunto de métodos para aprender categorías o acciones sin datos etiquetados, como los métodos para agrupar ejemplos con arreglo a su similitud o para aprender una nueva categoría por analogía con categorías conocidas, entre otros. Como explicaré en un capítulo posterior, a los humanos se les da muy bien percibir similitudes y analogías abstractas, pero hasta ahora no existen métodos que hayan tenido mucho éxito en este tipo de aprendizaje no supervisado de la IA. El propio Yann LeCun reconoce que “el aprendizaje no supervisado es la materia oscura de la IA”. En otras palabras, para la IA general, casi todo el aprendizaje tendrá que ser no supervisado, pero nadie ha dado todavía con el tipo de algoritmos necesarios para hacer ese aprendizaje no supervisado con buenos resultados.
Los humanos cometen errores constantemente, incluso (o especialmente) al volante; cualquiera de nosotros podría haber chocado con ese autobús si hubiéramos tenido que sortear los sacos de arena. Pero los humanos también tienen una competencia fundamental de la que carecen todos los sistemas de IA actuales: el sentido común. Tenemos un amplio conocimiento de fondo del mundo, tanto en el aspecto físico como en el social. Tenemos una idea bastante clara de cómo es probable que vayan a comportarse los objetos –tanto inanimados como vivos–, y utilizamos ese conocimiento para decidir cómo actuar en una situación determinada. Podemos deducir el motivo de los montones de sal en la carretera aunque nunca hayamos conducido con nieve. Sabemos relacionarnos socialmente con otros seres humanos, así que podemos hacer contacto visual, señales con las manos y otros gestos para compensar un semáforo estropeado durante un apagón. En general, sabemos que debemos ceder el paso a un autobús de transporte público, aunque en teoría tengamos prioridad. He puesto un ejemplo del tráfico, pero los seres humanos utilizamos el sentido común –casi siempre de forma subconsciente– en todas las facetas de la vida. Mucha gente cree que hasta que los sistemas de IA no tengan el mismo sentido común que los humanos, no podremos confiar en que sean totalmente autónomos en situaciones complejas del mundo real.

¿Qué ha aprendido mi red?
Hace unos años, Will Landecker, entonces estudiante de posgrado en mi grupo de investigación, entrenó una red neuronal profunda para clasificar fotografías en dos categorías: “contiene un animal” y “no contiene un animal”. La red se entrenó con fotos como las de la figura 3 y obtuvo muy buenos resultados con las imágenes de prueba. Pero ¿qué aprendió realmente la red? Will llevó a cabo un análisis minucioso y se encontró con una respuesta inesperada: en parte, la red había aprendido a clasificar las imágenes con fondo borroso como “contiene un animal”, tanto si había verdaderamente un animal como si no.[14] Las fotos de naturaleza de los conjuntos de entrenamiento y de prueba seguían una regla importante en fotografía: el foco es el sujeto de la foto. Cuando el sujeto de la foto es un animal, el animal es el foco y el fondo está borroso, como en la figura 3A. Cuando el sujeto de la foto es el fondo, como en la figura 3B, no se desenfoca nada. Para desilusión de Will, su red no había aprendido a reconocer animales, sino que utilizaba pistas más simples –como los fondos borrosos– que estadísticamente estaban asociadas a la presencia de animales.
Este es un ejemplo de un fenómeno habitual en el aprendizaje automático. La máquina aprende lo que observa en los datos, no lo que nosotros (los humanos) podríamos observar. Si hay asociaciones estadísticas en los datos de entrenamiento, aunque sean irrelevantes para la tarea en cuestión, la máquina aprenderá eso, no lo que nosotros queríamos que aprendiera. Si la máquina hace una prueba con nuevos datos que incluyan las mismas asociaciones estadísticas, parecerá que ha aprendido a resolver la tarea. Pero la máquina puede fallar de forma inesperada, como le ocurrió a la red de Will con las imágenes de animales que no tenían un fondo borroso. En el lenguaje del aprendizaje automático, la red de Will se “sobreajustó” a su conjunto de entrenamiento específico y, por tanto, no pudo aplicar bien lo aprendido a otras imágenes que no fueran las del entrenamiento.
En los últimos años, varios equipos han investigado si las ConvNet entrenadas en ImageNet y otros grandes conjuntos de datos se han sobreajustado de esa forma a sus datos de entrenamiento. Un grupo ha demostrado que, si las ConvNet se entrenan con imágenes descargadas de internet (como las de ImageNet), tienen más problemas con imágenes tomadas por un robot mientras se desplaza por una casa con una cámara.[15] Parece que las vistas aleatorias de objetos domésticos pueden ser muy distintas de las fotos que la gente cuelga en la web. Otros grupos han demostrado que una modificación superficial de las fotos, como difuminar o llenar de puntos una imagen, cambiar algunos colores o rotar varios objetos de la escena, pueden hacer que las ConvNet cometan errores significativos cuando esas perturbaciones no impiden que los humanos reconozcan los objetos.[16] Esta inesperada fragilidad de las ConvNet –incluso de aquellas que supuestamente “superan a los humanos en el reconocimiento de objetos”– indica que se están ajustando en exceso a sus datos de entrenamiento y aprendiendo algo distinto de lo que intentamos enseñarles.
Una IA sesgada
La poca fiabilidad de las ConvNet puede desembocar en errores embarazosos y quizá perjudiciales. En 2015, Google vivió una situación de pesadilla para su reputación cuando presentó una función de etiquetado automático de fotos (mediante una ConvNet) en su aplicación Fotos. Además de etiquetar correctamente imágenes con descripciones genéricas como “aviones”, “coches” y “graduación”, la red neuronal asignó a un selfi en el que aparecían dos afroamericanos la etiqueta de “gorilas”, como se muestra en la figura 4. (Después de pedir muchas disculpas, la solución inmediata de la empresa fue eliminar la etiqueta “gorilas” de la lista de categorías posibles).
Estos errores de clasificación, repugnantes y muy ridiculizados, son embarazosos para las empresas implicadas, pero con frecuencia se han visto errores más sutiles debidos a sesgos raciales o de género en sistemas de visión basados en el aprendizaje profundo. Los sistemas comerciales de reconocimiento facial, por ejemplo, tienden a ser más precisos con los rostros masculinos blancos que con los rostros femeninos o no blancos.[17] Los programas de detección facial tienden a veces a pasar por alto los rostros de piel oscura y a clasificar los rostros asiáticos como “parpadeantes” (figura 5).

Kate Crawford, investigadora de Microsoft y activista en favor de la equidad y la transparencia en la IA, destaca que los rostros contenidos en un conjunto de datos muy utilizado para entrenar sistemas de reconocimiento facial son en un 77,5 por ciento de hombres y en un 83,5 por ciento de blancos. Esto no es nada raro, porque las imágenes se descargaron a partir de búsquedas en internet, donde existe un sesgo a favor de personas famosas o poderosas, que son predominantemente blancas y masculinas.
Por supuesto, estos sesgos en los datos de entrenamiento de la IA reflejan los sesgos de nuestra sociedad, pero la generalización en el mundo real de sistemas de IA entrenados con datos sesgados puede agravarlos y causar daños considerables. Por ejemplo, los sistemas de reconocimiento facial se utilizan cada vez más como forma “segura” de identificar a las personas en las transacciones con tarjetas de crédito, los controles de los aeropuertos y las cámaras de seguridad, y puede que no falte mucho para que se utilicen como método de identificación en los sistemas de votación, entre otras aplicaciones. La más mínima diferencia de precisión entre unos grupos raciales y otros puede tener consecuencias perjudiciales para los derechos civiles y el acceso a servicios vitales.

En conjuntos de datos específicos es posible mitigar estos sesgos si se encarga a seres humanos que se aseguren de que las fotos (o cualquier otro tipo de datos) mantengan el equilibrio en su representación de, por ejemplo, grupos raciales o de género. Pero para ello es necesario que las personas que organizan los datos sean conscientes de ello y realicen su tarea de forma cuidadosa. Además, muchas veces es difícil detectar los sesgos sutiles y sus efectos. Por ejemplo, un grupo de investigación observó que su sistema de IA –entrenado con un gran conjunto de fotos de personas en diferentes situaciones– a veces se equivocaba y clasificaba a un hombre como “mujer” cuando aparecía en una cocina, un entorno en el que el conjunto de datos tenía más ejemplos de mujeres.[18] En general, este tipo de sesgo sutil puede ser evidente a posteriori, pero es difícil de detectar con antelación.
El problema del sesgo en las aplicaciones de IA ha sido objeto de mucha atención en los últimos tiempos, con numerosos artículos, talleres e incluso institutos de investigación académica dedicados a este tema. ¿Los conjuntos de datos que se utilizan para entrenar la IA deben reflejar fielmente los sesgos de nuestra sociedad –como suelen hacer en la actualidad–, o habría que retocarlos específicamente para cumplir objetivos de reforma social? ¿Y quién debería poder concretar los objetivos o hacer los retoques?
Enséñame cómo lo has hecho
¿Recuerdan cuando, en el colegio, el profesor escribía en rojo “enséñame cómo lo has hecho” en los deberes de matemáticas? Para mí, explicar cómo lo había hecho era la parte menos divertida de aprender matemáticas, pero seguramente era la más importante, porque decir cómo había deducido mi respuesta demostraba que verdaderamente había entendido lo que estaba haciendo, que había captado las abstracciones correctas y había llegado a la respuesta como era debido. Además, enseñar cómo lo había hecho también ayudaba a mi profesor a saber por qué cometía determinados errores.
En general, se puede confiar en que una persona sabe lo que hace si es capaz de explicar cómo ha llegado a una respuesta o a una decisión. Sin embargo, “enseñar cómo lo han hecho” no es algo que las redes neuronales profundas –la base de los sistemas modernos de IA– puedan hacer así como así. Volvamos a la tarea de identificar objetos como “perros” y “gatos” que describí en el capítulo 4. Recordemos que una red neuronal convolucional decide qué objeto hay en una imagen que le llega mediante una secuencia de operaciones matemáticas (convoluciones) propagadas a través de muchas capas. En una red de tamaño razonable, pueden hacerse hasta miles de millones de operaciones aritméticas. Sería fácil programar el ordenador para que imprima una lista de todas las sumas y multiplicaciones hechas por una red para una entrada determinada, pero esa lista no nos permitiría saber absolutamente nada de cómo ha llegado la red a su respuesta. Una lista de mil millones de operaciones no es una explicación que un humano pueda entender. Ni siquiera los humanos que entrenan redes profundas, en general, pueden mirar bajo el capó y explicar las decisiones que toman sus redes. La revista Technology Review, del MIT, llamó a esta impenetrabilidad “el oscuro secreto en el corazón de la IA”.[19] Lo que preocupa es que, si no entendemos cómo funcionan los sistemas de IA, no podemos confiar realmente en ellos ni predecir en qué circunstancias cometerán errores.
Los seres humanos tampoco pueden explicar siempre sus procesos mentales, y, en general, no es posible mirar “bajo el capó” y hurgar en el cerebro de otra persona (o en sus “instintos”) para averiguar cómo ha llegado a una decisión concreta. Pero los humanos tendemos a confiar en que otros humanos dominan tareas cognitivas básicas como el reconocimiento de objetos y la comprensión del lenguaje. En parte, confiamos en los demás cuando creemos que su forma de pensar es como la nuestra. En la mayoría de los casos, suponemos que los demás seres humanos con los que nos encontramos han tenido experiencias vitales bastante similares a las nuestras y, por tanto, que se basan en los mismos conocimientos básicos, creencias y valores que nosotros a la hora de percibir, describir y tomar decisiones sobre el mundo. En resumen, en nuestra relación con otras personas, tenemos lo que los psicólogos llaman una teoría de la mente: un modelo de los conocimientos y objetivos de la otra persona en situaciones concretas. Nadie tiene una “teoría de la mente” similar en relación con sistemas de IA como las redes profundas, por lo que es más difícil confiar en ellos.
No es extraño que uno de los nuevos campos más de moda de la IA sea el que llaman “IA explicable”, “IA transparente” o “aprendizaje automático interpretable”. Estos términos designan la investigación sobre cómo conseguir que los sistemas de IA –en especial las redes profundas– expliquen sus decisiones de manera comprensible para los humanos. Los investigadores de este terreno han concebido astutas formas para visualizar los elementos que ha aprendido una red neuronal convolucional y, en algunos casos, determinar qué partes de la información de entrada pesan más en la decisión de salida. La IA explicable es un campo que avanza con rapidez, pero todavía no se ha conseguido crear un sistema de aprendizaje profundo capaz de explicarse a sí mismo en términos humanos.
Engañar a las redes neuronales profundas
Hay otra dimensión más en la cuestión de la fiabilidad de la IA: los investigadores han descubierto que para los humanos es asombrosamente fácil engañar a las redes neuronales profundas para que cometan errores. Es decir, si queremos engañar deliberadamente a un sistema de este tipo, resulta que hay una terrible cantidad de maneras de hacerlo.
Engañar a los sistemas de inteligencia artificial no es nuevo. Quienes llenan de spam nuestros correos electrónicos, por ejemplo, llevan décadas en una carrera armamentística con los programas centrados en su detección. Pero los ataques a los que parecen ser vulnerables los sistemas de aprendizaje profundo son al mismo tiempo más sutiles y más preocupantes.
¿Recuerdan AlexNet, de la que hablé en el capítulo 5? Era la red neuronal convolucional que ganó el concurso de ImageNet de 2012 e inició el dominio de las ConvNet en gran parte del mundo de la IA actual. Recordarán que la precisión de AlexNet (con las cinco mejores conjeturas) en ImageNet fue del 85 por ciento, con lo que eliminó a todos los demás competidores y asombró al mundo de la visión por ordenador. Sin embargo, un año después de la victoria de AlexNet, apareció un artículo de investigación escrito por Christian Szegedy, de Google, y varios otros, con el título engañosamente suave de “Intrigantes propiedades de las redes neuronales”.[20] Una de las “propiedades intrigantes” descritas en el ensayo era que resultaba fácil engañar a AlexNet.
En concreto, los autores del artículo habían descubierto que podían coger una foto de ImageNet que AlexNet había clasificado acertadamente y con gran seguridad (por ejemplo, “autobús escolar”) y distorsionarla con cambios muy pequeños y específicos en sus píxeles, de modo que la imagen distorsionada les pareciera completamente igual a los humanos, pero AlexNet ahora la clasificara con un grado de seguridad muy alto como algo completamente diferente (por ejemplo, “avestruz”). A la imagen distorsionada le dieron el nombre de “ejemplo antagónico”. La figura 6 muestra varios ejemplos de imágenes originales y sus gemelas antagónicas. ¿No notan la diferencia? ¡Enhorabuena! Se ve que son humanos.

Szegedy y sus colaboradores crearon un programa informático que, con cualquier foto de ImageNet correctamente clasificada por AlexNet, podía encontrar cambios específicos en la foto para crear un nuevo ejemplo antagónico que a los humanos les pareciera inalterado pero que hiciera que AlexNet asignara una categoría incorrecta con la máxima seguridad.
Es importante señalar que Szegedy y sus colaboradores vieron que esta vulnerabilidad a los ejemplos antagónicos no era exclusiva de AlexNet, demostrando que otras redes neuronales convolucionales –con diferentes arquitecturas, hiperparámetros y conjuntos de entrenamiento– presentaban vulnerabilidades similares. Llamar a esto una “propiedad intrigante” de las redes neuronales es más o menos como decir que un agujero en el casco de un crucero de lujo es una “faceta del barco que da que pensar”. Intrigante, sí, y hace falta investigar más, pero, si no se arregla la fuga, el barco se va a pique.

Poco después de la publicación del artículo de Szegedy y sus colegas, un grupo de la Universidad de Wyoming publicó un artículo con un título más directo: “Las redes neuronales profundas son fáciles de engañar”.[21] Utilizando un método computacional inspirado en la biología denominado algoritmos genéticos,[22] el grupo de Wyoming fue capaz de “desarrollar” por ordenador imágenes que a los humanos les parecían ruido blanco pero a las que AlexNet y otras redes neuronales convolucionales asignaban categorías concretas de objetos con una seguridad superior al 99 por ciento. La figura 7 muestra algunos ejemplos. El grupo de Wyoming observó que las redes neuronales profundas (DNN por sus siglas en inglés) “ven estos objetos como ejemplos casi perfectos de imágenes reconocibles”, lo que “[suscita] dudas sobre la verdadera capacidad de generalización de las DNN y las posibilidades de que se haga un uso de las soluciones que emplean DNN que acabe saliendo caro [es decir, aplicaciones maliciosas]”.[23]
De hecho, estos dos artículos y otros descubrimientos posteriores en este sentido suscitaron no solo dudas sino auténtica alarma en el mundo del aprendizaje profundo. Si los sistemas de aprendizaje profundo, tan eficaces en visión por ordenador y otras tareas, pueden ser engañados tan fácilmente con manipulaciones que no confunden a los humanos, ¿cómo podemos decir que estas redes “aprenden como los humanos” o “igualan o superan a los humanos” en sus capacidades? Está claro que aquí estamos ante algo muy distinto de la percepción humana. Y si estas redes se van a utilizar para la visión por ordenador en el mundo real, más vale que nos aseguremos de que están protegidas contra los piratas informáticos que utilizan este tipo de manipulaciones para engañarlas.
Todo esto ha revitalizado la pequeña comunidad investigadora que se dedica al “aprendizaje antagónico”, es decir, al desarrollo de estrategias de defensa contra posibles antagonistas (humanos) que podrían atacar los sistemas de aprendizaje automático. Los investigadores sobre aprendizaje antagónico suelen empezar por mostrar formas posibles de atacar los sistemas actuales, y algunas de las demostraciones recientes han sido asombrosas. En el campo de la visión por ordenador, un grupo de investigadores ha desarrollado un programa capaz de crear monturas de gafas con dibujos específicos que engañan a un sistema de reconocimiento facial para que se equivoque e identifique al usuario como otra persona (figura 8).[24] Otro grupo ha desarrollado unas pegatinas pequeñas y discretas que pueden colocarse en una señal de tráfico y hacen que un sistema de visión basado en ConvNet –del tipo de los utilizados en los coches autónomos– clasifique erróneamente la señal (por ejemplo, identifica una señal de stop como una señal de límite de velocidad).[25] Un tercer grupo ha presentado un posible ataque antagónico contra redes neuronales profundas empleadas en el análisis de imágenes médicas: demostraron que no es difícil alterar una imagen de rayos X o de microscopio de forma imperceptible para los humanos pero que hace que una red cambie su dictamen de, por ejemplo, un 99 por ciento de seguridad en que la imagen no muestra cáncer a un 99 por ciento de seguridad en que sí hay cáncer.[26] Este grupo subraya que el personal hospitalario u otros profesionales podrían utilizar ese tipo de ataques para crear diagnósticos fraudulentos y así cobrar a las compañías de seguros por más (y lucrativas) pruebas de diagnóstico.

Estos son solo algunos ejemplos de los posibles ataques que han imaginado diversos grupos de investigación. Muchos de ellos exhiben una solidez asombrosa: funcionan en varias redes distintas, incluso cuando se las entrena con conjuntos de datos diferentes. Y la visión por ordenador no es el único campo en el que se puede engañar a las redes; los investigadores también han diseñado ataques que engañan a las redes neuronales profundas relacionadas con el lenguaje en aspectos como el reconocimiento del habla y el análisis de texto. Es de suponer que, a medida que estos sistemas se vayan extendiendo en el mundo real, los usuarios malintencionados descubran en ellos muchas otras vulnerabilidades.
Aprender a comprender estos posibles ataques y defenderse de ellos es un área actual de investigación importante, pero, aunque se han encontrado soluciones para tipos concretos de ataques, todavía no existe un método de defensa general. Como en cualquier otro campo de la seguridad informática, los avances conseguidos hasta ahora son más bien como un “juego del topo”, en el que se detecta y se defiende un agujero de seguridad, pero aparecen otros que necesitan nuevas defensas. Ian Goodfellow, un experto en IA que forma parte del equipo de Google Brain, explica: “En estos momentos se puede hacer casi todo lo malo que se nos pueda ocurrir hacerle a un modelo de aprendizaje automático […], y defenderlo es verdaderamente muy difícil”.[27]
Aparte del problema inmediato de cómo defenderse de los ataques, la existencia de ejemplos antagónicos da más resonancia a la pregunta que he hecho antes: ¿Qué están aprendiendo estas redes? En concreto, ¿qué están aprendiendo para que sea tan fácil engañarlas? O quizá más importante, ¿nos estamos engañando a nosotros mismos cuando pensamos que estas redes han aprendido verdaderamente los conceptos que intentamos enseñarles?
A mi juicio, el problema fundamental es de comprensión. Veamos la figura 6, en la que AlexNet confunde un autobús escolar con un avestruz. ¿Por qué es tan improbable que le pase a un ser humano? Aunque AlexNet funciona muy bien en ImageNet, los humanos entendemos muchas cosas sobre los objetos que vemos que no saben ni AlexNet ni otros sistemas de IA actuales.

Sabemos cómo son los objetos en tres dimensiones y podemos imaginárnoslos a partir de una foto bidimensional. Sabemos cuál es la función de un objeto determinado, qué papel desempeñan las partes del objeto en su función general y en qué contextos suele aparecer. Cuando vemos un objeto nos acordamos de haber visto otros iguales en distintas circunstancias y desde otros puntos de vista, además de haberlos percibido en otras modalidades sensoriales (recordamos el tacto de un objeto determinado, cómo huele, quizá cómo suena cuando se deja caer, etcétera). Todos estos conocimientos previos contribuyen a la capacidad humana de identificar con claridad un objeto concreto. Incluso los mejores sistemas de visión artificial carecen de este tipo de conocimiento y de la solidez que eso les otorgaría.
He oído decir a algunos investigadores de IA que los humanos también somos vulnerables a nuestros propios tipos de “ejemplos antagónicos”: las ilusiones ópticas. Igual que AlexNet clasifica un autobús escolar como un avestruz, los humanos somos susceptibles de cometer errores de percepción (por ejemplo, nos parece que la línea superior de la figura 9 es más larga que la inferior, aunque en realidad ambas tienen la misma longitud). Pero los errores que cometemos los humanos son muy distintos de los que cometen las redes neuronales convolucionales: nuestra capacidad de reconocer objetos en escenas cotidianas ha evolucionado hasta ser muy sólida porque dependemos de ella para sobrevivir. A diferencia de las ConvNet actuales, la percepción humana (y animal) está muy regulada por la cognición, la comprensión basada en el contexto de la que he hablado antes. Además, las ConvNet que se utilizan hoy en día en las aplicaciones de visión por ordenador suelen ser totalmente de “prealimentación”, mientras que el sistema visual humano tiene muchas más conexiones de “retroalimentación” (es decir, en dirección inversa) que de “prealimentación”. Aunque los neurocientíficos aún no comprenden la función de toda esta retroalimentación, se podría aventurar que al menos algunas de esas conexiones de retroalimentación consiguen prevenir la vulnerabilidad a ejemplos antagónicos como los casos a los que son susceptibles las ConvNets. Si es así, ¿por qué no dar a las ConvNet el mismo tipo de retroalimentación? Es un área en la que se está investigando, pero es muy difícil y no ha tenido tanto éxito como las redes de prealimentación.
Jeff Clune, investigador de IA de la Universidad de Wyoming, hizo una analogía muy estimulante cuando señaló que hay un gran interés en saber si el aprendizaje profundo es “verdadera inteligencia” o un “Hans el listo”.[28] Hans el listo fue un caballo alemán de principios del siglo xx que, según su dueño, podía hacer cálculos aritméticos y entendía alemán. El caballo respondía a preguntas como “¿Cuánto es quince dividido por tres?” golpeando con la pezuña la cifra correcta. Después de que Hans el listo se convirtiera en una celebridad internacional, una minuciosa investigación reveló que el caballo no entendía las preguntas ni los conceptos matemáticos que se le planteaban, sino que daba los golpes en función de unas señales sutiles que daba inconscientemente quien le preguntaba. Hans el listo se ha convertido en una forma de llamar a cualquier individuo (o programa) que da la impresión de comprender pero que, en realidad, reacciona ante las señales involuntarias del entrenador. ¿El aprendizaje profundo tiene “verdadera comprensión” o es más bien un Hans el listo informático que responde a señales superficiales encerradas en los datos? Esta duda es hoy objeto de acalorados debates en el mundo de la IA, con el agravante de que los investigadores de la IA no están necesariamente de acuerdo sobre la definición de “verdadera comprensión”.
Por un lado, las redes neuronales profundas, entrenadas mediante aprendizaje supervisado, funcionan extraordinariamente bien (aunque todavía lejos de la perfección) en muchos problemas de visión por ordenador y en otros campos como el reconocimiento del habla y la traducción de idiomas. Estas redes, gracias a sus impresionantes capacidades, están saliendo rápidamente del mundo de la investigación para emplearse en aplicaciones del mundo real como la búsqueda en internet, los coches autónomos, el reconocimiento facial, los asistentes virtuales y los sistemas de recomendación, y cada vez resulta más difícil imaginar la vida sin estas herramientas de IA. Por otro lado, es engañoso decir que las redes profundas “aprenden solas” o que su entrenamiento es “similar al aprendizaje humano”. Además de reconocer el éxito de estas redes, hay que matizar que pueden fallar de forma inesperada debido al sobreajuste a sus datos de entrenamiento, los efectos de cola larga y la vulnerabilidad a la piratería informática. Además, los motivos de las redes neuronales profundas a la hora de tomar decisiones son muchas veces difíciles de entender, por lo que es difícil predecir y solucionar los fallos. Los investigadores trabajan sin cesar para que las redes neuronales profundas sean más fiables y transparentes, pero sigue habiendo una pregunta sin respuesta: si estos sistemas carecen de una comprensión similar a la humana, ¿es inevitable que sean frágiles, poco fiables y vulnerables a los ataques? ¿Y cómo debe influir eso en nuestras decisiones sobre la utilización de sistemas de IA en el mundo real? El próximo capítulo examina algunas de las formidables dificultades que entraña intentar encontrar el equilibrio entre los beneficios de la IA y los riesgos de su falta de fiabilidad y su uso indebido.
Notas:
[1] Los lectores que siguieron las elecciones presidenciales estadounidenses de 2016 reconocerán el juego de palabras del eslogan de los partidarios de Bernie Sanders, “Feel the Bern”.
[2] E. Brynjolfsson y A. McAfee, “The Business of Artificial Intelligence”, Harvard Business Review, julio de 2017.
[3] O. Tanz, “Can Artificial Intelligence Identify Pictures Better than Humans?”, Entrepreneur, 1 de abril de 2017, www.entrepreneur.com/article/283990.
[4] D. Vena, “3 Top AI Stocks to Buy Now», Motley Fool, 27 de marzo de 2017, www. fool.com/investing/2017/03/27/3-top-ai-stocks-to-buy-now.aspx.
[5] Citado en C. Metz, “A New Way for Machines to See, Taking Shape in Toronto”, The New York Times, 28 de noviembre de 2017, www.nytimes.com/2017/11/28/tech- nology/artificial-intelligence-research-toronto.html.
[6] Citado en J. Tanz, “Soon We Won’t Program Computers. We’ll Train Them Like Dogs”, Wired, 17 de mayo de 2016.
[7] De la conferencia de Harry Shum en la Microsoft Faculty Summit, Redmond, Washington, junio de 2017.
[8] Este tema se analiza en profundidad en J. Lanier, Who Owns the Future ?(Nueva York: Simon & Schuster, 2013).
[9] Política de privacidad del cliente de Tesla, consultada el 7 de diciembre de 2018, www.tesla.com/about/legal.
[10] T. Bradshaw, “Self-Driving Cars Prove to Be Labour-Intensive for Humans”, Financial Times, 8 de julio de 2017.
[11] “Ground Truth Data sets for Autonomous Vehicles”, Mighty AI, consultado el 7 de diciembre de 2018, mty.ai/adas/.
[12] “Deep Learning in Practice: Speech Recognition and Beyond”, EmTech Digital video, 23 de mayo de 2016, events.technologyreview.com/emtech/digital/16/video/ watch/andrew-ng-deep-learning.
[13] Y. Bengio, “Machines That Dream”, en The Future of Machine Intelligence: Perspectives from Leading Practitioners, ed. D. Beyer (Sebastopol, Calif.: O’Reilly Media), p. 14.
[14] W. Landecker et al., “Interpreting Individual Classifications of Hierarchical Networks”, en Proceedings of the 2013 IEEE Symposium on Computational Intelligence and Data Mining (2013), 32–38.
[15] M. R. Loghmanietal, “Recognizing Objects in-the-Wild: Where Do We Stand?”, en IEEE International Conference on Robotics and Automation (2018), 2170–77.
[16] H. Hosseini et al., “On the Limitation of Convolutional Neural Networks in Recognizing Negative Images”, en Proceedings of the 16th IEEE International Conference on Machine Learning and Applications (2017), 352–358; R. Geirhos et al., “Generalisation in Humans and Deep Neural Networks”, Advances in Neural Information Processing Systems 31 (2018): 7549–61; M. Alcorn et al., “Strike (with) a Pose: Neural Networks Are Easily Fooled by Strange Poses of Familiar Objects”, arXiv:1811.11553 (2018).
[17] M. Orcutt, “Are Face Recognition Systems Accurate? Depends on Your Race”, Technology Review, 6 de julio de 2016, www.technologyreview.com/s/601786/are-face- recognition-systems-accurate-depends-on-your-race.
[18] J. Zhao et al., “Men Also Like Shopping: Reducing Gender Bias Amplification Using Corpus-Level Constraints”, en Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing (2017).
[19] W. Knight, “The Dark Secret at the Heart of AI”, Technology Review, 11 de abril de 2017, www.technologyreview.com/s/604087/the-dark-secret-at-the-heart-of-ai/.
[20] C. Szegedy et al., “Intriguing Properties of Neural Networks”, en Proceedings of the International Conference on Learning Representations (2014).
[21] A. Nguyen, J. Yosinski y J. Clune, “Deep Neural Networks Are Easily Fooled: High Confidence Predictions for Unrecognizable Images”, en Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2015), 427–436.
[22] Véase, por ejemplo, M. Mitchell, An Introduction to Genetic Algorithms (Cambridge, Mass.: MIT Press, 1996).
[23] Nguyen, Yosinski, y Clune, “Deep Neural Networks Are Easily Fooled”.
[24] M. Sharif et al., “Accessorize to a Crime: Real and Stealthy Attacks on State- of-the-Art Face Recognition”, en Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security (2016), 1528–1540.
[25] K. Eykholt et al., “Robust Physical-World Attacks on Deep Learning Visual Classification”, en Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2018), 1625–34.
[26] S. G. Finlayson et al., “Adversarial Attacks on Medical Machine Learning”, Science 363, núm. 6433 (2019): 1287–1289.
[27] Citado en W. Knight, “How Long Before AI Systems Are Hacked in Creative New Ways?”, Technology Review, 15 de diciembre de 2016, www.technologyreview. com/s/603116/how-long-before-ai-systems-are-hacked-in-creative-new-ways.
[28] J. Clune, “How Much Do Deep Neural Networks Understand About the Images They Recognize?”, diapositivas de conferencias (2016), consultadas el 7 de diciembre de 2018, c4dm.eecs.qmul.ac.uk/horse2016/HORSE2016Clune.pdf.
Este texto pertenece al libro Inteligencia Artificial. Guía par seres pensantes que, con traducción de María Luisa Rodríguez Tapia, ha publicado la editorial Capitán Swing.
